Présentation de la partie IV
Cette quatrième partie est une introduction aux concepts de la
programmation parallèle et présente les modèles à mémoire partagée et
à mémoire répartie. Il n'est pas nécessaire de posséder un
super-calculateur parallèle pour pouvoir exprimer des algorithmes
concurrents ou réaliser des applications réparties. Nous définissons
dans ce préambule les différents termes utilisés dans les chapitres
suivants.
Dans le cadre de la séquentialité, une instruction d'un programme
s'exécute après une autre. On parle alors de dépendance causale. Ces
programmes possèdent la propriété de déterminisme. Pour un même jeu de
données en entrée, un même programme termine ou bien ne termine pas,
et dans le cas où il termine, produit le même résultat. Le
déterminisme indique qu'une cause a un et un seul effet. Les seules
exceptions, déjà rencontrées en Objective CAML, proviennent des fonctions
prenant en entrée une information extérieure au programme, comme
la fonction Sys.time.
Dans le cadre de la programmation parallèle, un programme est découpé
en plusieurs processus actifs. Chacun de ces processus est
séquentiel, mais plusieurs instructions, appartenant aux
différents processus, sont exécutées en parallèle, c'est-à-dire
<< en même temps >>. La séquentialité se transforme en concurrence. On
parle alors d'indépendance causale. Une cause peut avoir plusieurs
effets, mutuellement exclusifs (un seul effet se produit). Une
conséquence immédiate est de perdre la propriété de déterminisme : un
même programme, pour une même donnée, termine ou ne termine pas en
pouvant produire lorsqu'il termine des résultats différents.
Pour contrôler l'exécution d'un programme parallèle, il est nécessaire
d'utiliser deux nouvelles notions :
-
la synchronisation qui introduit une attente d'une condition
sur plusieurs processus;
- la communication pour l'envoi d'informations d'un ou plusieurs
processus à un ou plusieurs processus.
Du point de vue de la causalité, la synchronisation assure que
plusieurs causes indépendantes doivent s'être produites avant que
l'effet puisse avoir lieu. La communication possède une contrainte
temporelle : un message ne peut pas être reçu avant d'avoir été émis.
La communication peut s'effectuer selon plusieurs modes :
communication d'un processus à un autre (point-à-point) ou en
diffusion (un-à-tous ou tous-à-tous).
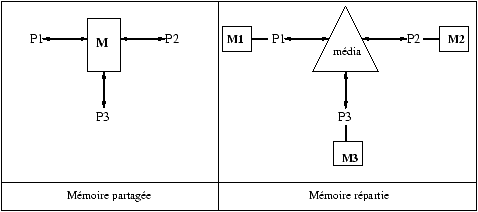
Les deux modèles de programmation parallèle, décrits à la figure
17.13, diffèrent sur le contrôle de l'exécution par les formes
de synchronisation et de communication.
Figure 17.13 : Modèles de parallélisme
Chaque processus Pi correspond à un processus
séquentiel. L'ensemble de ces processus, interagissant sur une mémoire
commune (M), ou communiquant via un média, constitue une
application parallèle.
Modèle à mémoire partagée
La communication dans le modèle à mémoire partagée est
implicite. L'information est transmise lors de l'écriture dans une
zone de la mémoire partagée, et récupérée quand un autre processus
vient lire cette zone. Par contre la synchronisation doit être
explicite, en utilisant des instructions élémentaires de gestion de
l'exclusion mutuelle et d'attente sur condition.
Ce modèle est utilisé dès que l'on se sert de manière concurrente une
ressource commune. On peut citer en particulier la construction des
systèmes d'exploitation.
Modèle à mémoire répartie
Dans ce modèle chaque processus séquentiel Pi possède sa
propre mémoire privée Mi. Il est le seul à y avoir
accès. Les processus doivent alors communiquer pour transférer de
l'information à travers un média assurant ces
transferts. La difficulté de ce modèle provient de l'implantation
du média. Les programmes s'en chargeant s'appellent des protocoles.
Ceux-ci sont organisés en couches. Les protocoles de haut niveau,
implantant des services élaborés, utilisent les couches de plus
bas niveaux.
Il existe plusieurs types de communication selon la capacité du média
à stocker de l'information et selon le caractère bloquant ou non de
l'émission et de la réception. On parle de communications
synchrones quand le transfert d'information n'est possible qu'après
une synchronisation globale des processus émetteur et récepteur. Dans
ce cas l'émission et la réception peuvent être bloquantes.
Si le
média possède une capacité de stockage, il peut conserver des
messages émis en vue de leur acheminement ultérieur. La communication
peut être alors asynchrone et l'émission non bloquante. Il est
toutefois nécessaire
de spécifier la capacité de stockage du média, l'ordre d'acheminement, les
délais et la fiabilité des transmissions.
Enfin si l'émission est non
bloquante avec un média ne pouvant conserver les messages, on obtient
une communication évanescente : seuls les processus récepteurs prêts
reçoivent le message émis qui est alors perdu pour les autres.
Dans le modèle à mémoire répartie la communication est explicite
alors que la synchronisation est implicite (elle est en fait produite
par la communication). C'est le dual du modèle à mémoire
partagée.
Parallélisme physique et logique
Le modèle à mémoire répartie est valable dans le cas de parallélisme
physique (réseau d'ordinateurs) ou logique (processus Unix
communiquant par tubes de communication ou
processus légers
communiquant par canaux). Il n'y a pas de valeurs globales connues par
tous les processus (comme une horloge globale).
Le modèle à mémoire partagée est plus proche du parallélisme physique,
une même mémoire est effectivement partagée. Néanmoins, rien n'empêche
de simuler une mémoire partagée sur un réseau d'ordinateurs.
Cette quatrième partie va donc montrer comment construire des
applications parallèles en Objective CAML en utilisant les deux modèles
présentés. Elle s'appuie principalement sur la bibliothèque
Unix, qui interface les appels système Unix à Objective CAML, et
la bibliothèque Thread qui implante les processus légers. La
bibliothèque Unix est en grande partie portée sous Windows,
en particulier les fonctions sur les descripteurs de fichier.
Ceux-ci sont utilisés pour lire et écrire sur des fichiers, mais aussi
pour les tubes de communication (pipe) et pour les
prises de communication réseau (socket).
Le chapitre 18 décrit les traits essentiels de la
bibliothèque Unix en s'intéressant tout particulièrement à la
communication d'un processus vers l'extérieur ou vers d'autres
processus. La notion de processus de ce chapitre est celui de
<< processus lourd >> à la Unix. Leur création s'effectue
par l'appel système fork qui duplique le contexte d'exécution
et la zone mémoire des données en créant une filiation entre
processus. L'interaction entre processus est réalisée soit par des
signaux, soit à travers des tubes de communication.
Le chapitre 19 reprend la notion de processus en présentant
les processus légers de la bibliothèque Thread. À la
différence des processus lourds précédents, ceux-ci ne dupliquent que
le contexte d'exécution d'un processus existant. La zone de données
est donc commune au thread créateur et au thread créé.
Selon le style de programmation, les processus légers d'Objective CAML
permettent de rendre compte du modèle de parallélisme à mémoire
partagée (style impératif) ou du modèle à mémoire distincte (style
purement fonctionnel). La bibliothèque Thread comprend
plusieurs modules permettant le lancement et l'arrêt de
threads, la gestion de verrou pour l'exclusion mutuelle,
l'attente sur condition et la communication entre threads via
des canaux propres aux threads. Dans ce modèle, il n'y a pas
gain de temps d'exécution d'un programme, y compris sur les machines
multi-processeurs. Néanmoins l'expression d'algorithmes parallèles y
est grandement facilitée.
Le chapitre 20 se consacre à la fabrication d'applications
réparties sur le réseau Internet. Il présente ce réseau du point de
vue des protocoles de bas niveau. Grâce aux prises de communication,
plusieurs processus s'exécutant sur différentes machines peuvent
communiquer entre eux. La communication à travers des sockets
est une communication point-à-point asynchrone. Le rôle des différents
processus entrant en jeu dans la communication d'une application
répartie est en générale asymétrique. C'est le cas dans une
architecture client-serveur. Le serveur est un processus acceptant
des requêtes et tâchant d'y répondre. Le client, autre processus,
envoie une requête au serveur en espérant une réponse. De nombreux
services accessibles sur le réseau Internet suivent cette
architecture.
Le chapitre 21 présente une bibliothèque
et deux applications
complètes. La bibliothèque permet de définir la communication
entre clients et serveurs à partir d'un protocole donné.
La première application reprend les robots du chapitre
17 pour en donner une version répartie.
La deuxième application construit un serveur HTTP
pour la gestion d'un formulaire de requêtes
reprenant les éléments de la gestion d'associations
présentée au chapitre 6.