C'est une notion que vous connaissez déjà!
En effet, pour utiliser une fonction, nous avons dit qu'il fallait
regarder sa spécification -- et non sa définition --, spécification qui
est une description, une « abstraction » de ce que rend la fonction.
;;;
;;;
(define (fn d) ...)
Ainsi, on peut considérer qu'il y a une barrière entre la fin de la
spécification et sa définition proprement dite et, lors d'une
utilisation, on n'a pas besoin (et il faudrait même se l'interdire) de
franchir cette barrière.
Nous avons vu aussi que, bien entendu, du côté de celui qui écrit la
définition de la fonction -- on dit qu'il l'implante --, il faut que
cette implantation réponde à la spécification.
Souvent,
on ne peut pas
implanter une fonction toute seule sans tenir compte de l'implantation
d'autres fonctions, pour avoir un ensemble cohérent.
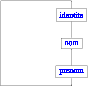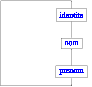
Aussi, regroupe-t-on toutes ces fonctions dans ce qu'on appelle une
barrière d'abstraction. Comme pour les fonctions, une
barrière d'abstraction a un aspect abstrait (c'est l'ensemble des
spécifications des fonctions) et un aspect concret (c'est
l'implantation des fonctions).
Prenons un exemple (uniquement didactique): nous voudrions manipuler
l'identité des individus, identité qui est composé d'un nom et d'un
prénom. Les fonctions utiles sont alors
identite (qui crée une
identité à partir d'un nom et d'un prénom),
prenom (qui rend le
prénom d'une identité donnée) et
nom (qui rend le nom d'une
identité donnée).
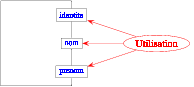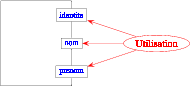
Ensuite, lorsque l'on veut définir une fonction dont une donnée ou le résultat
est un élément du domaine de la barrière d'abstraction, on n'utilise
que les fonctions de la barrière d'abstraction (on s'interdit
d'utiliser la connaissance que l'on pourrait avoir de l'implantation
de cette barrière d'abstraction):
Mais, bien entendu, il faut aussi implanter cette abstraction.
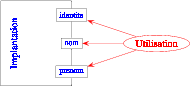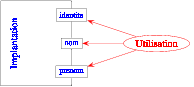
L'intérêt (fondamental en génie logiciel) est que l'on peut ensuite
changer facilement l'implantation de la barrière d'abstraction (en
général pour avoir une implantation plus performante): il suffit de
modifier cette implantation et, comme les fonctions utilisatrices de
la barrière d'abstraction ne sont définies qu'avec les fonctions de
cette barrière, sans utiliser la connaissance des détails de
l'implantation, elles restent parfaitement valides.
Prenons l'exemple de l'identité des individus. La spécification de la
barrière d'abstraction est:
;;;
;;;
;;;
;;;
;;;
;;;
;;;
Écrivons une fonction qui, étant donnée une identité,
rend la chaîne de caractères composée du prénom de l'individu, suivi
d'un espace et terminée par le nom de l'individu:
;;;
;;;
;;;
(define (ident->string id)
(string-append (prenom id) " " (nom id)))
Il ne reste plus qu'à implanter la barrière d'abstraction. Vous pensez
peut-être qu'il n'y a qu'une solution: un n-uplet qui comporte deux
chaînes de caractères. Mais, tout de suite, on voit qu'il y en a deux
selon que l'on mette le nom avant ou après le prénom. Ces deux
solutions étant très proches, on ne voit pas pourquoi on changerait
(mais, lorsque l'on écrit des fonctions sur cette structure de
données, il faut savoir dans quel cas on est: il est alors beaucoup
plus parlant d'utiliser les fonctions
nom et
prenom que
les fonctions
car et
cadr). Voici cette implantation:
;;;
;;;
;;;
(define (identite nom prenom)
(list nom prenom))
;;;
;;;
(define (nom id)
(car id))
;;;
;;;
(define (prenom id)
(cadr id))
Mais on pourrait aussi utiliser le type
Paragraphe, en
mémorisant le prénom dans la première ligne et le nom dans la seconde
ligne:
;;;
;;;
;;;
(define (identite nom prenom)
(paragraphe (list prenom nom)))
;;;
;;;
(define (nom id)
(cadr (lignes id)))
;;;
;;;
(define (prenom id)
(car (lignes id)))
Et il y en a (au moins) une quatrième! L'identité des individus
intervient dans tous les fichiers qui comportent des informations sur
des personnes, par exemple le fichier de la scolarité qui contient
votre cursus, vos notes... Or, dans ce fichier, les identités sont
mémorisées sous forme d'une chaîne de caractères obtenue en
concaténant le nom, puis une virgule et enfin le prénom. Ainsi,
n'est-il pas aberrant d'avoir une autre implantation de cette barrière
d'abstraction (nous ne donnons pas les définitions des fonctions
string-avant-virgule et
string-apres-virgule car elles
sont hors programme):
;;;
;;;
(define (identite nom prenom)
(string-append nom "," prenom))
;;;
;;;
(define (nom id)
(string-avant-virgule id))
;;;
;;;
(define (prenom id)
(string-apres-virgule id))
avec
;;;
;;;
;;;
;;;
;;;
;;;
Par la suite, nous voudrons souvent avoir plusieurs implantations
d'une même barrière d'abstraction et tester des fonctions
utilisatrices de cette barrière d'abstraction avec chaque implantation
de la barrière. Afin de minimiser les « copier--coller », nous
utiliserons une architecture logicielle particulière que nous
décrivons ci-dessous sur notre exemple.
Ainsi,
les définitions Scheme des différentes fonctions de l'exemple
ci-dessus sont écrites dans deux fichiers:
-
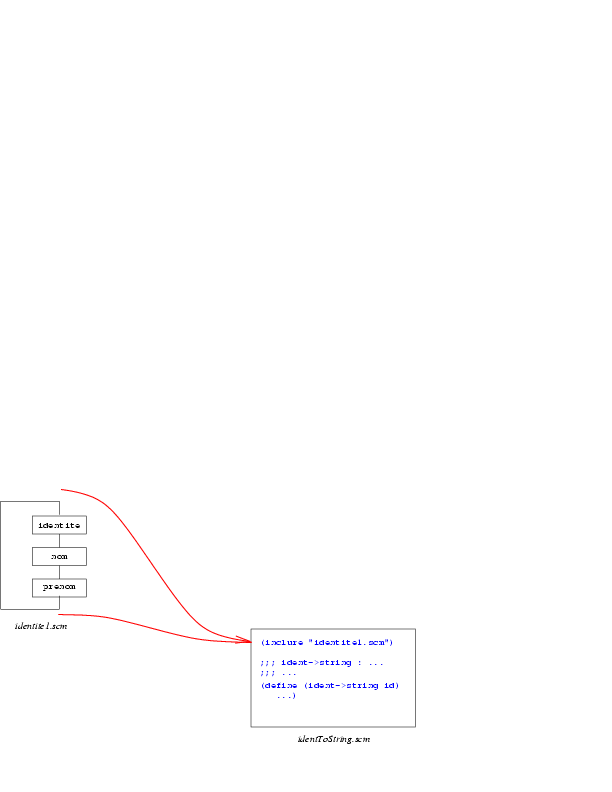
un fichier, nommé identite1.scm, contient une première
version de la barrière d'abstraction (spécification et
implantation),
- un fichier, nommé identToString.scm, contient une
définition, utilisatrice de cette barrière d''abstraction, de la
fonction ident->string.
La définition de cette dernière fonction utilisant la barrière
d'abstraction, nous demandons que le fichier
identite1.scm soit
inclus en début de fichier grâce à la fonction
inclure qui a
comme spécification:
;;;
;;;
;;;
Ainsi, le fichier
identToString.scm commence par:
;;;;
(inclure "identite1.scm")
On peut schématiser cette architecture par:
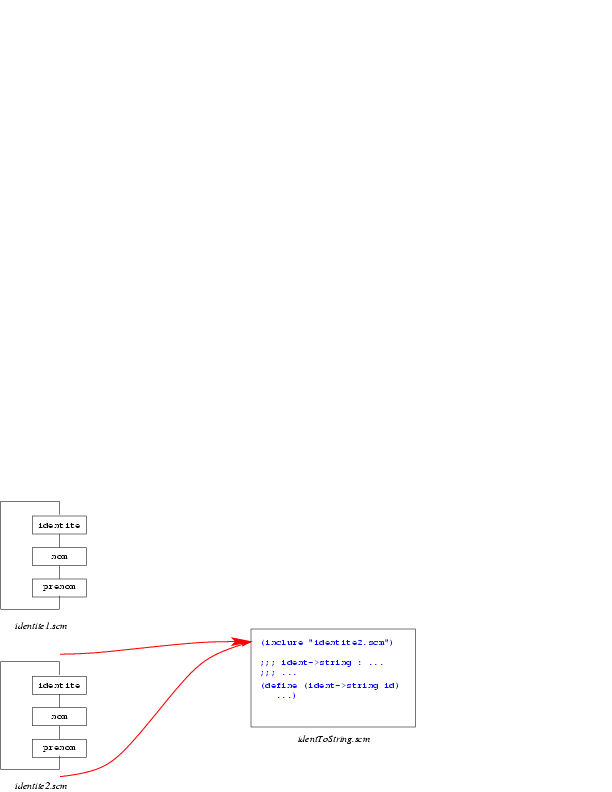
Si l'on veut une autre implantation de la barrière d'abstraction, il suffit
-
de l'écrire dans un fichier nommé identite2.scm et,
- dans le fichier identToString.scm de remplacer
(inclure "identite1.scm") par (inclure
"identite2.scm"):
Remarque: dans la pratique,
-
pour que le test affiche la version de la barrière d'abstraction
utilisée, dans le fichier identToString.scm,
-
nous avons défini une fonction qui rend le nom du fichier où
se trouve la barrière d'abstraction et
- nous appliquons cette fonction dans l'application de
inclure et dans un « display » qui affiche ce nom lors de
l'exécution;
- cette définition est écrite plusieurs fois, avec les noms des
fichiers des différentes versions, et nous les commentons systématiquement
sauf celle que nous voulons tester.
Ainsi, notre fichier
identToString.scm (qui permet de tester
trois versions de la barrière d'abstraction) est:
;;;;
;;;;
;
(define (version-identite) "identite2.scm")
;
(inclure (version-identite))
;;;
;;;
;;;
(define (ident->string id)
(string-append (prenom id) " " (nom id)))
;;;
(display (string-append "Essai avec " (version-identite)))
(verifier ident->string
(ident->string (identite "Curie" "Pierre")) == "Pierre Curie")