Requêtes sur une base de données
La réalisation d'une base de données, de son interface et de son
langage de requêtes est un projet trop ambitieux pour le cadre de ce
livre et pour les connaissances en Objective CAML du lecteur rendu à ce
point. Pourtant, en restreignant le problème et en profitant au
mieux des possibilités offertes par la programmation fonctionnelle,
nous allons pouvoir réaliser un outil intéressant pour le
traitement des requêtes. Nous verrons, en particulier, comment
utiliser les itérateurs ainsi que l'application partielle pour formuler et
exécuter des requêtes. Nous montrerons également l'utilisation
d'un type de données encapsulant des valeurs fonctionnelles.
Tout au long de cette application, nous utiliserons en guise d'exemple
une base de données rassemblant les informations sur
les adhérents d'une association. Elle est supposée être contenue
dans le fichier association.dat.
Format des données
La plupart des logiciels classiques de base de données utilisent un
format dit << propriétaire >> pour stocker les informations qu'ils
manipulent. Cependant, il est généralement possible de les sauver
sous un format texte auquel on peut donner la forme suivante :
-
la base est une suite de fiches séparées par des
retour-chariot ;
- chaque fiche est une suite de champs séparés par un
caractère quelconque que nous supposerons ici être le caractère
':' ;
- un champ est une chaîne de caractères qui ne
contient ni retour-chariot, ni le caractère
':' ;
- la première fiche est la liste des noms associés aux champs
séparés par
'|'.
Le fichier de l'association débute par :
Num|Nom|Prenom|Adresse|Tel|Email|Pref|Date|Montant
0:Chailloux:Emmanuel:Université P6:0144274427:ec@lip6.fr:mail:25.12.1998:100.00
1:Manoury:Pascal:Laboratoire PPS::pm@lip6.fr:adr:03.03.1997:150.00
2:Pagano:Bruno:Cristal:0139633963::adr:25.12.1998:150.00
3:Baro:Sylvain::0144274427:baro@pps.fr:mail:01.03.1999:50.00
La signification des champs est la suivante :
-
Num est le numéro d'adhérent ;
- Nom, Prenom, Adresse, Tel et Email
parlent d'eux-mêmes ;
- Pref indique comment l'adhérent désire recevoir les
informations : par courrier postal (adr), par courrier
électronique (mail) ou par téléphone (tel) ;
- Date et Montant sont respectivement la date et le
montant de la dernière cotisation perçue.
Il nous faut dès à présent choisir la représentation que le
programme adoptera pour stocker une base de données. Une
alternative s'offre : soit une liste de fiches, soit un tableau de
fiches. La liste présente l'avantage d'être aisément
modifiable : l'ajout et la suppression d'une fiche sont des
opérations simples. Le tableau, pour sa part, offre un accès en
temps constant à n'importe quelle fiche. Comme notre but est de
travailler sur l'ensemble des fiches et non pas sur certaines en
particulier, chaque requête devra traiter la totalité des
fiches. On peut donc choisir une structure de liste. La même
alternative se pose pour les fiches : listes ou tableaux de chaînes
de caractères ? Cette fois-ci, la réponse est inverse car, d'une
part le format d'une fiche est figé pour toute la base, il n'est
donc pas question de rajouter de nouveaux champs ; d'autre part, selon
les traitements envisagés, seuls certains champs seront utiles, il
est donc important d'y accéder rapidement.
La solution la plus naturelle pour une fiche serait d'avoir recours
à un tableau indexé par le nom des champs. Un tel type n'étant
pas possible en Objective CAML, nous allons le remplacer
par un tableau classique (indexé par des entiers) et une fonction
associant à un champ, l'indice du tableau lui correspondant.
# type data_card = string array ;;
# type data_base = { card_index : string -> int ; data : data_card list } ;;
L'accès au champ de nom n d'une fiche dc de la base
db est réalisé par la fonction :
# let field db n (dc:data_card) = dc.(db.card_index n) ;;
val field : data_base -> string -> data_card -> string = <fun>
Le type de dc a été forcé à data_card pour
contraindre la fonction field à n'accepter que des tableaux
de chaînes de caractères et non des tableaux quelconques.
Voici un petit exemple en guise d'illustration :
# let base_ex =
{ data = [ [|"Chailloux"; "Emmanuel"|] ; [|"Manoury";"Pascal"|] ] ;
card_index = function "Nom"->0 | "Prenom"->1 | _->raise Not_found } ;;
val base_ex : data_base =
{card_index=<fun>;
data=[[|"Chailloux"; "Emmanuel"|]; [|"Manoury"; "Pascal"|]]}
# List.map (field base_ex "Nom") base_ex.data ;;
- : string list = ["Chailloux"; "Manoury"]
L'expression field base_ex "Nom" s'évalue comme une
fonction qui prend une fiche et renvoie son champ
"Nom". Par l'utilisation de List.map, cette fonction
est exécutée sur chacune des fiches de la base base_ex
et on obtient la liste des résultats : soit la liste des champs
"Nom" de la base.
Cet exemple nous permet de voir comment nous souhaitons utiliser la
fonctionnalité dans notre programme. Ici, l'application partielle de
field nous permet de définir une fonction d'accès à un
champ précis, utilisable sur un nombre quelconque de fiches. Cela
nous permet aussi de voir que notre implantation de cette même
fonction field souffre d'un léger défaut car, alors que nous
accédons toujours au même champ, son indice est tout de même
recalculé à chaque fois. Pour cette raison, nous lui préférons
l'implantation suivante :
# let field base name =
let i = base.card_index name in fun (card:data_card) -> card.(i) ;;
val field : data_base -> string -> data_card -> string = <fun>
Ici, après application de deux arguments, l'indice du champ est
effectivement calculé et sert pour toutes les applications
ultérieures.
Lecture d'une base depuis un fichier
Depuis Objective CAML, un fichier contenant une base est une suite de lignes.
Notre travail va consister à lire chacune d'entre elles comme une chaîne
de caractères puis à la découper en repérant les séparateurs et à construire d'une part
les données et d'autre part la fonction d'indexation des champs.
Utilitaires de traitement de ligne
Nous nous dotons d'une fonction split qui découpe une
chaîne de caractères selon un caractère séparateur. Cette
fonction utilise la fonction suffix retournant le suffixe
d'une chaîne s à partir d'une position i. On
utilise pour cela trois fonctions prédéfinies :
-
String.length donne la longueur d'une chaîne;
- String.sub retourne la sous-chaîne de s à partir de la position i de longueur l;
- String.index_from calcule dans la chaîne s, à partir de la
position n, la position de la première occurrence du caractère c.
# let suffix s i = try String.sub s i ((String.length s)-i)
with Invalid_argument("String.sub") -> "" ;;
val suffix : string -> int -> string = <fun>
# let split c s =
let rec split_from n =
try let p = String.index_from s n c
in (String.sub s n (p-n)) :: (split_from (p+1))
with Not_found -> [ suffix s n ]
in if s="" then [] else split_from 0 ;;
val split : char -> string -> string list = <fun>
La seule chose à noter dans l'implantation de ces fonctions est la
gestion des exceptions, en particulier, l'exception
Not_found.
Calcul de la structure data_base
Obtenir un tableau de chaînes à partir d'une liste ne pose pas de
problème : le module Array fournit la fonction nécessaire
(of_list). Le calcul de la fonction d'indice à partir d'une
liste de noms de champs pourrait paraître plus compliqué mais le
module List fournit tous les outils dont nous avons besoin.
Nous partons d'une liste de chaînes et nous devons obtenir une
fonction qui à une chaîne associe un indice qui correspond à sa place
dans la liste.
# let mk_index list_names =
let rec make_enum a b = if a > b then [] else a::(make_enum (a+1) b) in
let list_index = (make_enum 0 ((List.length list_names) - 1)) in
let assoc_index_name = List.combine list_names list_index in
function name -> List.assoc name assoc_index_name ;;
val mk_index : 'a list -> 'a -> int = <fun>
Pour obtenir la fonction d'association entre noms de champ et indices,
nous construisons la liste des indices que nous combinons avec la
liste de noms. Nous obtenons une liste d'association de type
string * int list. Pour chercher l'indice associé à un nom nous
avons recours à la fonction assoc de la bibliothèque
List qui est dédiée à cette tâche. Le résultat de
make_index est une fonction qui prend un nom et appelle
assoc avec ce nom sur la liste d'association précédemment
construite.
Nous pouvons maintenant définir la fonction de lecture des fichiers
contenant une base au format imposé.
# let read_base name_file =
let channel = open_in name_file in
let split_line = split ':' in
let list_names = split '|' (input_line channel) in
let rec read_file () =
try
let data = Array.of_list (split_line (input_line channel )) in
data :: (read_file ())
with End_of_file -> close_in channel ; []
in
{ card_index = mk_index list_names ; data = read_file () } ;;
val read_base : string -> data_base = <fun>
La lecture des enregistrements du fichier est réalisée par la fonction
auxiliaire read_file qui opère récursivement sur le canal
d'entrée. Le cas de base de la récurrence correspond à la fin du
fichier signalée par l'exception End_of_file. Notons que
nous profitons de ce cas retournant la liste vide pour refermer le
canal.
Nous pouvons maintenant charger le fichier de notre association :
# let base_ex = read_base "association.dat" ;;
val base_ex : data_base =
{card_index=<fun>;
data=
[[|"0"; "Chailloux"; "Emmanuel"; "Universit\233 P6"; "0144274427";
"ec@lip6.fr"; "mail"; "25.12.1998"; "100.00"|];
[|"1"; "Manoury"; "Pascal"; "Laboratoire PPS"; ...|]; ...]}
Principes généraux des traitements
La richesse et la complexité du traitement de l'ensemble des
données d'une base sont proportionnelles à la richesse et à la
complexité du langage de requêtes utilisé. Puisqu'ici, notre
volonté est d'utiliser Objective CAML comme langage de requêtes, il n'y
a a priori pas de limite à l'expression des requêtes !
Cependant, nous souhaitons également fournir quelques outils simples
de manipulation des fiches et de leurs données. Pour obtenir cette
simplicité, il nous faut nécessairement limiter la trop grande
richesse du langage Objective CAML en posant quelques objectifs et principes
généraux de traitement.
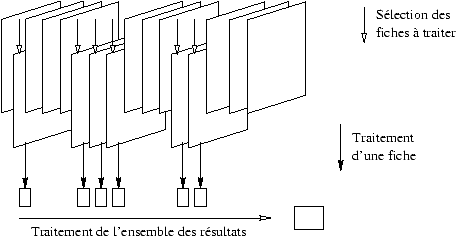
L'objectif d'un traitement de données est d'obtenir ce que l'on
appelle un état de la base. On peut décomposer la
construction d'un état en trois étapes :
-
sélection, selon un critère donné, d'un ensemble des fiches ;
- traitement individuel de chacune des fiches sélectionnées ;
- traitement de l'ensemble des données collectées sur chacune
des fiches.
Cette décomposition est illustrée à la figure
6.1.
Figure 6.1 : décomposition d'une requête
Suivant cette décomposition, nous avons besoin de trois fonctions
possédant les types suivants :
-
(data_card -> bool) -> data_card list -> data_card list
- (data_card -> 'a) -> data_card list -> 'a list
- ('a -> 'b -> 'b) -> 'a list -> 'b -> 'b
Objective CAML nous fournit trois fonctions d'ordre supérieur, ou
itérateurs, présentés à la page ??, qui répondent à
notre spécification :
# List.find_all ;;
- : ('a -> bool) -> 'a list -> 'a list = <fun>
# List.map ;;
- : ('a -> 'b) -> 'a list -> 'b list = <fun>
# List.fold_right ;;
- : ('a -> 'b -> 'b) -> 'a list -> 'b -> 'b = <fun>
Nous pourrons les utiliser pour réaliser les trois étapes de
construction d'un état lorsque nous aurons fixé la valeur de leur
argument fonctionnel.
Pour certaines requêtes particulières, on
utilisera également :
# List.iter ;;
- : ('a -> unit) -> 'a list -> unit = <fun>
En effet, si le traitement d'un ensemble d'informations se limite à
leur affichage, il n'y a pas réellement de valeur à calculer.
Nous allons, dans les paragraphes suivants, voir comment définir des
fonctions exprimant les critères de sélection ainsi que quelques
traitements simples. Nous conclurons ce chapitre par un petit exemple
mettant en oeuvre ces fonctions selon le principe énoncé
ci-dessus.
Critères de sélection
Dans la pratique, la fonction booléenne qui exprime le critère de
sélection d'une fiche est obtenue par combinaison booléenne de
propriétés données sur tout ou partie des champs de la fiche.
Chaque champ d'une fiche, quoique donné comme une chaîne de
caractères, peut être porteur d'une information d'un autre type :
un flottant, une date, etc.
Critères de sélection sur un champ
La composante d'un critère de sélection concernant un champ
particulier sera, en général, obtenue à partir d'une fonction de type
data_base -> 'a -> string -> data_card -> bool.
Le paramètre de type 'a correspond au type de l'information
contenue dans le champ. L'argument de type string correspond
au nom du champ.
Informations de type chaînes de caractères
Nous définissons deux tests simples sur ces types de champ :
l'égalité avec une autre chaîne et la non vacuité.
# let eq_sfield db s n dc = (s = (field db n dc)) ;;
val eq_sfield : data_base -> string -> string -> data_card -> bool = <fun>
# let nonempty_sfield db n dc = ("" <> (field db n dc)) ;;
val nonempty_sfield : data_base -> string -> data_card -> bool = <fun>
Informations de type flottant
Pour réaliser des tests sur des informations de type flottant, il
suffit simplement d'opérer la conversion d'une valeur de type
string représentant un nombre décimal en une valeur de
type float. Voici quelques exemples obtenus à partir d'une
fonction générique
tst_ffield :
# let tst_ffield r db v n dc = r v (float_of_string (field db n dc)) ;;
val tst_ffield :
('a -> float -> 'b) -> data_base -> 'a -> string -> data_card -> 'b = <fun>
# let eq_ffield = tst_ffield (=) ;;
# let lt_ffield = tst_ffield (<) ;;
# let le_ffield = tst_ffield (<=) ;;
(* etc. *)
Ces trois fonctions sont de type :
data_base -> float -> string -> data_card -> bool.
Les dates
Ce type d'information est un peu plus complexe à traiter. Il
dépend de la représentation de la date dans la base et réclame
de définir un codage des comparaisons de dates.
Nous fixons qu'une date est représentée dans une fiche par une
chaîne de caractères au format jj.mm.aaaa. Pour les besoins
des comparaisons que nous souhaitons obtenir,
nous enrichissons ce
format en autorisant le remplacement du jour, du mois ou de l'année
par le caractère souligné ('_').
Les dates sont comparées selon l'ordre lexicographique sur des
triplets d'entiers de la forme (année, mois, jour). Pour
pouvoir exprimer des requêtes telles : << est antérieure à
juillet 1998 >>, on utilisera le motif de date :
"_.07.1998". La comparaison d'une
date avec un motif sera réalisée par la fonction
tst_dfield qui analysera le motif pour en extraire la
fonction de comparaison ad hoc. La définition de cette fonction
générique de test sur les dates nécessite un certain nombre de
fonctions auxiliaires.
On se donne deux fonctions de conversion de dates
(ints_of_string) et de motifs de dates
(ints_of_dpat) en triplets d'entiers. Le caractère
'_' d'un motif sera remplacé par l'entier 0 :
# let split_date = split '.' ;;
val split_date : string -> string list = <fun>
# let ints_of_string d =
try match split_date d with
[j;m;a] -> [int_of_string a; int_of_string m; int_of_string j]
| _ -> failwith "Bad date format"
with Failure("int_of_string") -> failwith "Bad date format" ;;
val ints_of_string : string -> int list = <fun>
# let ints_of_dpat d =
let int_of_stringpat = function "_" -> 0 | s -> int_of_string s
in try match split_date d with
[j;m;a] -> [ int_of_stringpat a; int_of_stringpat m;
int_of_stringpat j ]
| _ -> failwith "Bad date format"
with Failure("int_of_string") -> failwith "Bad date pattern" ;;
val ints_of_dpat : string -> int list = <fun>
Étant donnée une relation r sur les entiers, on écrit la
fonction d'application du test. C'est un codage de l'ordre
lexicographique prenant en compte la valeur particulière 0
que l'on ignore :
# let rec app_dtst r d1 d2 = match d1, d2 with
[] , [] -> false
| (0::d1) , (_::d2) -> app_dtst r d1 d2
| (n1::d1) , (n2::d2) -> (r n1 n2) || ((n1 = n2) && (app_dtst r d1 d2))
| _, _ -> failwith "Bad date pattern or format" ;;
val app_dtst : (int -> int -> bool) -> int list -> int list -> bool = <fun>
On définit enfin la fonction générique tst_dfield
qui prend comme arguments une relation r, une base de données db,
un motif dp, un nom de champ nm et une fiche dc. Cette
fonction vérifie que le motif et le champ extrait de la fiche satisfont
la relation.
# let tst_dfield r db dp nm dc =
r (ints_of_dpat dp) (ints_of_string (field db nm dc)) ;;
val tst_dfield :
(int list -> int list -> 'a) ->
data_base -> string -> string -> data_card -> 'a = <fun>
On l'applique alors à trois relations.
# let eq_dfield = tst_dfield (=) ;;
# let le_dfield = tst_dfield (<=) ;;
# let ge_dfield = tst_dfield (>=) ;;
Ces trois fonctions sont de type :
data_base -> string -> string -> data_card -> bool.
Composition de critères
Les tests que nous avons définis ci-dessus ont pour
trois premiers arguments une base de données, une valeur et le nom
d'un champ. Lorsque nous formulons des requêtes particulières,
les valeurs de ces trois arguments sont connues. Lorsque l'on
travaille sur la base base_ex, le test << est antérieure
à juillet 1998 >> s'écrit
# ge_dfield base_ex "_.07.1998" "Date" ;;
- : data_card -> bool = <fun>
En pratique, un test est donc une fonction de type
data_card -> bool. Nous voulons obtenir des combinaisons
booléennes des résultats de telles fonctions appliquées à une
même fiche. Nous nous donnons à cette fin l'itérateur ;
# let fold_funs b c fs dc =
List.fold_right (fun f -> fun r -> c (f dc) r) fs b ;;
val fold_funs : 'a -> ('b -> 'a -> 'a) -> ('c -> 'b) list -> 'c -> 'a = <fun>
Où b est la valeur de base, la fonction c sera le
connecteur booléen, fs la liste des fonctions de test sur
un champ et dc une fiche.
On obtient la conjonction et la
disjonction d'une liste de tests par :
# let and_fold fs = fold_funs true (&) fs ;;
val and_fold : ('a -> bool) list -> 'a -> bool = <fun>
# let or_fold fs = fold_funs false (or) fs ;;
val or_fold : ('a -> bool) list -> 'a -> bool = <fun>
Par commodité, on définit également la négation d'un test :
# let not_fun f dc = not (f dc) ;;
val not_fun : ('a -> bool) -> 'a -> bool = <fun>
On peut, par exemple, utiliser ces combinateurs pour définir une
fonction de sélection d'une fiche dont le champ date est compris
dans un intervalle donné :
# let date_interval db d1 d2 =
and_fold [(le_dfield db d1 "Date"); (ge_dfield db d2 "Date")] ;;
val date_interval : data_base -> string -> string -> data_card -> bool =
<fun>
Traitements et calculs
Il est difficile de prévoir ce que peut être a priori le
traitement d'une fiche ou de l'ensemble des données issues de ce
traitement. Néanmoins, on peut considérer deux grandes classes de
tels traitements : un calcul numérique ou le formatage de données
pour impression. Prenons un exemple de chacun des cas envisagés.
Formatage
On désire préparer pour l'impression une ligne contenant
l'identité d'un adhérent suivie d'un certain nombre
d'informations.
On commence par se donner l'opération inverse du découpage d'une
chaîne selon un caractère donné :
# let format_list c =
let s = String.make 1 c in
List.fold_left (fun x y -> if x="" then y else x^s^y) "" ;;
val format_list : char -> string list -> string = <fun>
Afin de construire la liste des champs d'information, on se donne la
fonction extract qui extrait d'une fiche un ensemble de
champs définis par une liste de noms :
# let extract db ns dc =
List.map (fun n -> field db n dc) ns ;;
val extract : data_base -> string list -> data_card -> string list = <fun>
On écrit enfin la fonction de formatage d'une ligne :
# let format_line db ns dc =
(String.uppercase (field db "Nom" dc))
^" "^(field db "Prenom" dc)
^"\t"^(format_list '\t' (extract db ns dc))
^"\n" ;;
val format_line : data_base -> string list -> data_card -> string = <fun>
L'argument ns est la liste des champs d'information
désirés. Les champs d'information sont séparés par le
caractère de tabulation ('\t') et la ligne se termine par un
retour-chariot.
On obtient l'affichage de la liste des noms et prénoms des
adhérents par :
# List.iter print_string (List.map (format_line base_ex []) base_ex.data) ;;
CHAILLOUX Emmanuel
MANOURY Pascal
PAGANO Bruno
BARO Sylvain
- : unit = ()
Calcul numérique
On veut calculer la somme des cotisations perçues pour un ensemble
de fiches. On obtient facilement ce chiffre en composant l'extraction
et la conversion du champ correspondant avec une fonction
d'addition. Pour alléger l'écriture, on définit un opérateur
infixe de composition :
# let (++) f g x = g (f x) ;;
val ++ : ('a -> 'b) -> ('b -> 'c) -> 'a -> 'c = <fun>
On utilise cet opérateur de composition dans la définition suivante :
# let total db dcs =
List.fold_right ((field db "Montant") ++ float_of_string ++ (+.)) dcs 0.0 ;;
val total : data_base -> data_card list -> float = <fun>
On peut l'appliquer à la totalité de la base :
# total base_ex base_ex.data ;;
- : float = 450
Un exemple
Nous donnons, pour conclure ce chapitre un petit exemple d'application
des principes exposés dans les paragraphes précédents.
Nous envisageons deux types de requêtes sur notre base :
-
l'édition de deux listes contenant chacune l'identité de
l'adhérent, puis, selon ses préférences, son adresse postale ou
son adresse électronique.
- l'édition d'un état des cotisations entre deux dates
données. Cet état contiendra la liste des nom, prénom, date et
montant des cotisations ainsi que le total de ces dernières.
Listes d'adresses
Pour obtenir ces listes, on sélectionne d'abord les fiches
pertinentes selon la valeur du champ
"Pref" puis on utilise la fonction de formatage
format_line :
# let adresses_postales db =
let dcs = List.find_all (eq_sfield db "adr" "Pref") db.data in
List.map (format_line db ["Adresse"]) dcs ;;
val adresses_postales : data_base -> string list = <fun>
# let adresses_electroniques db =
let dcs = List.find_all (eq_sfield db "mail" "Pref") db.data in
List.map (format_line db ["Email"]) dcs ;;
val adresses_electroniques : data_base -> string list = <fun>
État des cotisations
Le calcul de l'état des cotisations procède toujours selon le
même esprit : sélection puis traitement. Mais le traitement est
dédoublé en formatage des lignes puis calcul du total.
# let etat_cotisations db d1 d2 =
let dcs = List.find_all (date_interval db d1 d2) db.data in
let ls = List.map (format_line db ["Date";"Montant"]) dcs in
let t = total db dcs in
ls, t ;;
val etat_cotisations : data_base -> string -> string -> string list * float =
<fun>
Le résultat de cette requête est un couple contenant la liste des
chaînes d'information et le montant cumulé des cotisations.
Programme principal
Le programme principal de
l'application est essentiellement une boucle d'interaction avec
l'utilisateur qui affiche le résultat de la requête demandée
par menu. On y retrouve naturellement un style de programmation
impératif, même si l'affichage des résultats fait appel à un
itérateur.
# let main() =
let db = read_base "association.dat" in
let fin = ref false in
while not !fin do
print_string" 1: liste des adresses postales\n";
print_string" 2: liste des adresses électroniques\n";
print_string" 3: cotisations\n";
print_string" 0 sortie\n";
print_string"Votre choix : ";
match read_int() with
0 -> fin := true
| 1 -> (List.iter print_string (adresses_postales db))
| 2 -> (List.iter print_string (adresses_electroniques db))
| 3
-> (let d1 = print_string"Date de début : "; read_line() in
let d2 = print_string"Date de fin : "; read_line() in
let ls, t = etat_cotisations db d1 d2 in
List.iter print_string ls;
print_string"Total : "; print_float t; print_newline())
| _ -> ()
done;
print_string"bye\n" ;;
val main : unit -> unit = <fun>
Cet exemple sera repris au chapitre 21
pour le munir d'une interface utilisant un navigateur WEB.
Pour en faire plus
Une extension naturelle de notre exemple serait de munir la base d'une
indication de type associée à chaque champ de la base. Cette
information pourrait alors être exploitée pour définir des
opérateurs de comparaison généraux de type
data_base -> 'a -> string -> data_card -> bool où le nom du
champ (troisième argument) permettrait d'aiguiller sur les bonnes
fonctions de conversion et de test.