Interprète BASIC
L'application présentée dans cette section est un interprète de
programmes Basic. C'est donc un programme sachant exécuter d'autres
programmes écrits en Basic. Bien entendu, nous ne décrirons qu'un
langage restreint, il ne contient que les instructions suivantes :
-
PRINT expression
| |
Affiche le résultat de l'évaluation de l'expression. |
- INPUT variable
| |
Affiche un prompt à l'écran (?), attend qu'un
entier soit entré au clavier, et affecte la variable avec cette
valeur. |
- LET variable = expression
| |
Affecte la variable avec le résultat de l'évaluation de l'expression. |
- GOTO numéro de ligne
| |
Reprend l'exécution à la ligne mentionnée. |
- IF condition THEN numéro de ligne
| |
Reprend l'exécution à la ligne mentionnée si la condition
est vraie. |
- REM chaîne de caractères quelconque
| |
Commentaire sur une ligne. |
Chaque ligne d'un programme Basic est étiquetée par son numéro
de ligne et ne contient qu'une seule instruction. Par exemple, un programme
calculant puis affichant la factorielle d'un entier entré au clavier
s'écrit :
5 REM entree de l'argument
10 PRINT " factorielle de :"
20 INPUT A
30 LET B = 1
35 REM debut de la boucle
40 IF A <= 1 THEN 80
50 LET B = B * A
60 LET A = A - 1
70 GOTO 40
75 REM le resultat est affiche
80 PRINT B
Nous souhaitons de surcroît réaliser un mini-éditeur
fonctionnant sur le principe d'une boucle d'interaction. Il devra
rendre possible l'ajout de nouvelles lignes, l'affichage d'un programme et
l'évaluation.
L'exécution du programme précédent est lancée par la commande
RUN. Voici un exemple d'évaluation de ce programme :
> RUN
factorielle de : ? 5
120
Nous décomposons la réalisation de cet évaluateur en plusieurs
parties relativement distinctes :
- Description de la syntaxe abstraite
- : il faut définir
des types de données permettant de représenter les programmes
Basic ainsi que leurs constituants (lignes, instructions, expressions, etc.).
- Affichage du programme
- : cette partie consiste à transformer la
représentation interne des programmes Basic en chaînes de
caractères afin de les visualiser.
- Analyse lexicale et analyse syntaxique
- : ces deux parties
réalisent l'opération inverse, à savoir transformer une
chaîne de caractères en la représentation interne d'un
programme Basic (sa syntaxe abstraite).
- Évaluation
- : le coeur de l'évaluateur gouvernant
l'exécution du programme. Nous verrons qu'un langage fonctionnel
comme Objective CAML est particulièrement bien adapté à ce genre de
problème.
- Boucle d'interaction
- : elle met en oeuvre ce qui précède.
Syntaxe abstraite
La figure 6.2 présente la syntaxe concrète du Basic que nous allons implanter
par une grammaire sous la forme BNF. Cette façon de présenter la
syntaxe d'un langage est décrite au chapitre 11, page ??.
| Op_Unaire |
::= |
- | ! |
| Op_Binaire |
::= |
+ | - | * | / |
% |
| |
| |
= | < | > | <= |
>= | <> |
| |
| |
& | ' | ' |
| Expression |
::= |
entier |
| |
| |
variable |
| |
| |
"chaîne de caractères" |
| |
| |
Op_Unaire Expression |
| |
| |
Expression Op_Binaire Expression |
| |
| |
( Expression ) |
| Instruction |
::= |
REM chaîne de caractères |
| |
| |
GOTO entier |
| |
| |
LET variable = Expression |
| |
| |
PRINT Expression |
| |
| |
INPUT variable |
| |
| |
IF Expression THEN entier |
| |
| Ligne |
::= |
entier Instruction |
| |
| Programme |
::= |
Ligne |
| |
| |
Ligne Programme |
| |
| Commande |
::= |
Ligne | RUN | LIST | END |
Figure 6.2 : Grammaire BASIC
Remarquons que la définition des expressions ne garantit pas qu'une
expression bien formée soit évaluable. Par exemple, 1+"hello" est une expression et pourtant il n'est pas possible de
l'évaluer. Ce choix délibéré permet de simplifier la syntaxe abstraite
du langage Basic et de raccourcir l'analyse syntaxique. Le
prix à payer est la possibilité que des programmes Basic
syntaxiquement corrects puissent produire une erreur d'exécution
due à une incohérence de type.
La définition des types de données Objective CAML pour cette syntaxe
abstraite découle immédiatement de la définition de la syntaxe
concrète en utilisant un type somme :
# type op_unr = OPPOSE | NON ;;
# type op_bin = PLUS | MOINS | MULT | DIV | MOD
| EGAL | INF | INFEQ | SUP | SUPEQ | DIFF
| ET | OU ;;
# type expression =
ExpInt of int
| ExpVar of string
| ExpStr of string
| ExpUnr of op_unr * expression
| ExpBin of expression * op_bin * expression ;;
# type instruction =
Rem of string
| Goto of int
| Print of expression
| Input of string
| If of expression * int
| Let of string * expression ;;
# type ligne = { num : int ; inst : instruction } ;;
# type program = ligne list ;;
On définit les éléments de syntaxe abstraite pour les commandes du
mini-éditeur de programme :
# type phrase = Ligne of ligne | List | Run | End ;;
Il est d'usage d'alléger l'écriture des expressions arithmétiques
en autorisant le programmeur à ne pas mentionner toutes les
parenthèses. Par exemple, l'expression 1+3*4 est habituellement
interprétée comme 1+(3*4). On attribue, à cette fin, un entier
à chacun des opérateurs du langage :
# let priority_ou = function NON -> 1 | OPPOSE -> 7
let priority_ob = function
MULT | DIV -> 6
| PLUS | MOINS -> 5
| MOD -> 4
| EGAL | INF | INFEQ | SUP | SUPEQ | DIFF -> 3
| ET | OU -> 2 ;;
val priority_ou : op_unr -> int = <fun>
val priority_ob : op_bin -> int = <fun>
Ces entiers indiquent ce que l'on appelle la priorité des
opérateurs. Nous verrons comment elle est utilisée pour
l'affichage des programmes et l'analyse syntaxique.
Affichage des programmes
Pour afficher un programme contenu en mémoire, il faut savoir
transformer une ligne de programme, sous forme de syntaxe abstraite,
en une chaîne de caractères.
La conversion des opérateurs est immédiate :
# let pp_opbin = function
PLUS -> "+" | MULT -> "*" | MOD -> "%" | MOINS -> "-"
| DIV -> "/" | EGAL -> " = " | INF -> " < "
| INFEQ -> " <= " | SUP -> " > "
| SUPEQ -> " >= " | DIFF -> " <> " | ET -> " & " | OU -> " | "
let pp_opunr = function OPPOSE -> "-" | NON -> "!" ;;
val pp_opbin : op_bin -> string = <fun>
val pp_opunr : op_unr -> string = <fun>
L'affichage des expressions tiendra compte des règles de priorité
pour engendrer un parenthésage allégé. Par exemple, on ne
parenthèse une sous-expression à droite d'un opérateur que
lorsque son opérateur principal a une priorité inférieure à
l'opérateur principal de l'expression entière. De plus, les
opérateurs arithmétiques sont associatifs à gauche,
c'est-à-dire que l'expression 1-2-3 est implicitement
parenthésée comme (1-2)-3.
Pour ce faire, nous avons recours à deux fonctions auxiliaires
ppg et ppd pour traiter respectivement les
sous-arbres gauches et les sous-arbres droits. Ces fonctions prennent
deux paramètres, d'une part l'arbre d'expression à afficher mais
aussi la priorité de l'opérateur qui est en amont de cet arbre
afin de décider s'il y a lieu de parenthéser l'expression. Nous
distinguons les sous-arbres gauches des sous-arbres droits pour
traiter l'associativité des opérateurs. En cas d'égalité de
priorité des opérateurs on ne mettra pas de parenthèse pour
l'opérande gauche alors qu'elles sont indispensables dans le cas de
l'opérande droit comme dans les expressions 1-(2-3) et 1 + ( 2 + 3).
On considère l'arbre initial comme un sous-arbre gauche sous un
opérateur de priorité minimale (0).
Voici la fonction pp_expresssion d'affichage des expressions :
# let parenthese x = "(" ^ x ^ ")";;
val parenthese : string -> string = <fun>
# let pp_expression =
let rec ppg pr = function
ExpInt n -> (string_of_int n)
| ExpVar v -> v
| ExpStr s -> "\"" ^ s ^ "\""
| ExpUnr (op,e) ->
let res = (pp_opunr op)^(ppg (priority_ou op) e)
in if pr=0 then res else parenthese res
| ExpBin (e1,op,e2) ->
let pr2 = priority_ob op
in let res = (ppg pr2 e1)^(pp_opbin op)^(ppd pr2 e2)
(* parenthèse si la priorité n'est pas supérieure *)
in if pr2 >= pr then res else parenthese res
and ppd pr exp = match exp with
(* les sous-arbres droits ne diffèrent *)
(* que pour les opérateurs binaires *)
ExpBin (e1,op,e2) ->
let pr2 = priority_ob op
in let res = (ppg pr2 e1)^(pp_opbin op)^(ppd pr2 e2)
in if pr2 > pr then res else parenthese res
| _ -> ppg pr exp
in ppg 0 ;;
val pp_expression : expression -> string = <fun>
L'affichage des instructions utilise la fonction précédente sur les expressions. L'affichage d'une ligne ajoutera un numéro de ligne devant l'instruction.
# let pp_instruction = function
Rem s -> "REM " ^ s
| Goto n -> "GOTO " ^ (string_of_int n)
| Print e -> "PRINT " ^ (pp_expression e)
| Input v -> "INPUT " ^ v
| If (e,n) -> "IF "^(pp_expression e)^" THEN "^(string_of_int n)
| Let (v,e) -> "LET " ^ v ^ " = " ^ (pp_expression e) ;;
val pp_instruction : instruction -> string = <fun>
# let pp_ligne l = (string_of_int l.num) ^ " " ^ (pp_instruction l.inst) ;;
val pp_ligne : ligne -> string = <fun>
Analyse lexicale
Les analyses lexicale et syntaxique effectuent la transformation
inverse de l'affichage. Elles reçoivent une chaîne de
caractères et construisent un arbre de syntaxe. L'analyse lexicale
découpe le texte d'une ligne d'instruction en unités lexicales
indépendantes appelées lexèmes, dont le type Objective CAML suit :
# type lexeme = Lint of int
| Lident of string
| Lsymbol of string
| Lstring of string
| Lfin ;;
Nous avons rajouté un lexème particulier pour marquer la fin d'une
expression : Lfin. Il ne fait pas partie de la chaîne
analysée, mais sera engendré par la fonction d'analyse lexicale
(voir fonction lexer, page ??).
La chaîne que l'on souhaite analyser est conservée dans un
enregistrement contenant un champ modifiable indiquant l'indice
de la partie de la chaîne restant à parcourir. La taille de la
chaîne étant une information qui sera nécessaire
en de multiples occasions et qui ne varie pas, nous la stockons dans
l'enregistrement :
# type chaine_lexer = {chaine:string; mutable courant:int; taille:int } ;;
Cette représentation permet de définir l'analyse lexicale d'une
chaîne comme l'application d'une fonction à une valeur de type
chaine_lexer et rendant une valeur de type lexeme. La
modification de l'indice de la chaîne restant à parcourir se
fait par effet de bord.
# let init_lex s = { chaine=s; courant=0 ; taille=String.length s } ;;
val init_lex : string -> chaine_lexer = <fun>
# let avance cl = cl.courant <- cl.courant+1 ;;
val avance : chaine_lexer -> unit = <fun>
# let avance_n cl n = cl.courant <- cl.courant+n ;;
val avance_n : chaine_lexer -> int -> unit = <fun>
# let extrait pred cl =
let st = cl.chaine and ct = cl.courant in
let rec ext n = if n<cl.taille && (pred st.[n]) then ext (n+1) else n in
let res = ext ct
in cl.courant <- res ; String.sub cl.chaine ct (res-ct) ;;
val extrait : (char -> bool) -> chaine_lexer -> string = <fun>
Les fonctions suivantes extraient un lexème de la chaîne et
positionnent le caractère courant sur le prochain caractère
à traiter. Les deux fonctions auxiliaires :
extrait_int et
extrait_ident extraient respectivement un entier et un
identificateur.
# let extrait_int =
let est_entier = function '0'..'9' -> true | _ -> false
in function cl -> int_of_string (extrait est_entier cl)
let extrait_ident =
let est_alpha_num = function
'a'..'z' | 'A'..'Z' | '0' .. '9' | '_' -> true
| _ -> false
in extrait est_alpha_num ;;
val extrait_int : chaine_lexer -> int = <fun>
val extrait_ident : chaine_lexer -> string = <fun>
La fonction lexer utilise les deux fonctions précédentes
pour extraire un lexème.
# exception LexerErreur ;;
exception LexerErreur
# let rec lexer cl =
let lexer_char c = match c with
' '
| '\t' -> avance cl ; lexer cl
| 'a'..'z'
| 'A'..'Z' -> Lident (extrait_ident cl)
| '0'..'9' -> Lint (extrait_int cl)
| '"' -> avance cl ;
let res = Lstring (extrait ((<>) '"') cl)
in avance cl ; res
| '+' | '-' | '*' | '/' | '%' | '&' | '|' | '!' | '=' | '(' | ')' ->
avance cl; Lsymbol (String.make 1 c)
| '<'
| '>' -> avance cl;
if cl.courant >= cl.taille then Lsymbol (String.make 1 c)
else let cs = cl.chaine.[cl.courant]
in ( match (c,cs) with
('<','=') -> avance cl; Lsymbol "<="
| ('>','=') -> avance cl; Lsymbol ">="
| ('<','>') -> avance cl; Lsymbol "<>"
| _ -> Lsymbol (String.make 1 c) )
| _ -> raise LexerErreur
in
if cl.courant >= cl.taille then Lfin
else lexer_char cl.chaine.[cl.courant] ;;
val lexer : chaine_lexer -> lexeme = <fun>
Le principe de la fonction lexer est des plus simples, elle
filtre le caractère courant d'une chaîne et, suivant sa valeur,
rend le lexème correspondant en ayant avancé le caractère
courant de la chaîne jusqu'au caractère suivant. Cette approche
est bien adaptée car mis à part pour deux caractères, des
lexèmes différents peuvent se distinguer dès leur premier
caractère. Dans le cas de '<' nous sommes par contre obligés
d'examiner le caractère suivant pour savoir s'il s'agit de = ou
de > ce qui produira un lexème différent. De même pour le
caractère '>'.
Analyse syntaxique
L'unique difficulté de l'analyse syntaxique de notre langage
provient des expressions. En effet, la connaissance du début de
l'expression ne suffit pas pour déterminer sa structure. Supposons
que nous ayons analysé la portion de chaîne 1+2+3. Suivant ce
qui suit, par exemple : +4 ou *4, nous obtiendrons des arbres
d'expression dont la structure concernant 1+2+3 n'est pas la même
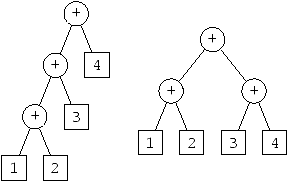
(voir figure 6.3).
Figure 6.3 : Basic : exemple d'arbres de syntaxe abstraite
Cependant, la structure de l'arbre correspondant à 1+2 est la
même dans les deux cas. Nous pouvons donc la construire. comme le
sort réservé à +3 est encore indéterminé, nous stockerons
temporairement cette information jusqu'à ce que nous possédions
suffisamment d'information pour pouvoir la traiter.
Nous allons procéder à la construction de l'arbre de syntaxe
abstraite en ayant recours à un automate à pile proche de
celui que construit l'outil yacc (voir page
??). Les lexèmes sont lus l'un après l'autre et
sont empilés tant que l'information n'est pas suffisante pour
construire l'expression. Lorsque nous savons décider de la structure
des éléments d'expressions empilés, nous les retirons de la pile
et les remplaçons par l'expression construite. Cette opération
s'appelle réduction.
Le type des éléments empilés est le suivant :
# type exp_elem =
Texp of expression (* expression *)
| Tbin of op_bin (* opérateur binaire *)
| Tunr of op_unr (* opérateur unaire *)
| Tpg (* parenthèse gauche *) ;;
Remarquons que les parenthèses droites ne sont pas stockées car
seules les parenthèses gauche sont significatives pour l'opération
de réduction.
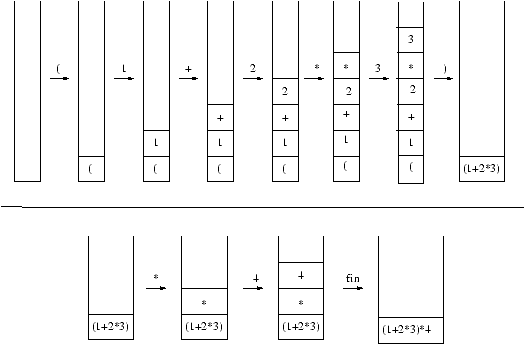
La figure 6.4 illustre le principe de l'utilisation de
la pile pour l'analyse de l'expression (1+2*3)+4. Le caractère
surmontant la flèche est le caractère courant de la chaîne.
Figure 6.4 : Basic : exemple de construction d'un arbre de syntaxe
abstraite
On définit l'exception suivante pour les erreurs de syntaxe.
# exception ParseErreur ;;
La première étape à effectuer est de retrouver les opérateurs
à partir des symboles :
# let symb_unr = function
"!" -> NON | "-" -> OPPOSE | _ -> raise ParseErreur
let symb_bin = function
"+" -> PLUS | "-" -> MOINS | "*" -> MULT | "/" -> DIV | "%" -> MOD
| "=" -> EGAL | "<" -> INF | "<=" -> INFEQ | ">" -> SUP
| ">=" -> SUPEQ | "<>" -> DIFF | "&" -> ET | "|" -> OU
| _ -> raise ParseErreur
let tsymb s = try Tbin (symb_bin s) with ParseErreur -> Tunr (symb_unr s) ;;
val symb_unr : string -> op_unr = <fun>
val symb_bin : string -> op_bin = <fun>
val tsymb : string -> exp_elem = <fun>
La fonction suivante (reduit) implante l'opération de
réduction de la pile. Il y a deux cas à considérer, la pile
commence par :
-
une expression suivie d'un opérateur unaire
- une expression suivie d'un opérateur binaire et d'une
expression.
De plus, reduit prend en argument la priorité minimale qu'un
opérateur doit avoir pour que la réduction de la pile ait
lieu. Pour réduire sans condition, il suffit de donner une
profondeur minimale nulle.
# let reduit pr = function
(Texp e)::(Tunr op)::st when (priority_ou op) >= pr
-> (Texp (ExpUnr (op,e)))::st
| (Texp e1)::(Tbin op)::(Texp e2)::st when (priority_ob op) >= pr
-> (Texp (ExpBin (e2,op,e1)))::st
| _ -> raise ParseErreur ;;
val reduit : int -> exp_elem list -> exp_elem list = <fun>
Notez que les éléments d'expressions sont empilés suivant l'ordre de
lecture, d'où la nécessité d'inverser les deux opérandes d'une
opération binaire.
La fonction principale de l'analyse syntaxique est la fonction
empile_ou_reduit qui, suivant le lexème donné en
argument, ajoute un nouvel élément dans la pile ou procède à
une réduction.
# let rec empile_ou_reduit lex stack = match lex , stack with
Lint n , _ -> (Texp (ExpInt n))::stack
| Lident v , _ -> (Texp (ExpVar v))::stack
| Lstring s , _ -> (Texp (ExpStr s))::stack
| Lsymbol "(" , _ -> Tpg::stack
| Lsymbol ")" , (Texp e)::Tpg::st -> (Texp e)::st
| Lsymbol ")" , _ -> empile_ou_reduit lex (reduit 0 stack)
| Lsymbol s , _
-> let symbole =
if s<>"-" then tsymb s
(* lever l'ambiguïté du symbole ``-'' *)
(* suivant la pile (i.e dernier exp_elem empilé) *)
else match stack
with (Texp _)::_ -> Tbin MOINS
| _ -> Tunr OPPOSE
in ( match symbole with
Tunr op -> (Tunr op)::stack
| Tbin op ->
( try empile_ou_reduit lex (reduit (priority_ob op)
stack )
with ParseErreur -> (Tbin op)::stack )
| _ -> raise ParseErreur )
| _ , _ -> raise ParseErreur ;;
val empile_ou_reduit : lexeme -> exp_elem list -> exp_elem list = <fun>
Une fois tous les lexèmes isolés et empilés, l'arbre de syntaxe
abstraite doit être finalement construit avec les éléments
restant dans la pile. C'est le but de la fonction
reduit_tout. Si l'expression à analyser est bien formée,
il ne doit plus rester dans la pile qu'un seul élément contenant
l'arbre de cette expression.
# let rec reduit_tout = function
| [] -> raise ParseErreur
| [Texp x] -> x
| st -> reduit_tout (reduit 0 st) ;;
val reduit_tout : exp_elem list -> expression = <fun>
La fonction parse_exp est la fonction principale de
l'analyse des expressions. Elle parcourt une chaîne de caractères, en
extrait les différents lexèmes et les passe à la fonction
empile_ou_reduit. L'analyse s'arrête lorsque le lexème
courant satisfait un prédicat passé en argument.
# let parse_exp fin cl =
let p = ref 0 in
let rec parse_un stack =
let l = ( p:=cl.courant ; lexer cl)
in if not (fin l) then parse_un (empile_ou_reduit l stack)
else ( cl.courant <- !p ; reduit_tout stack )
in parse_un [] ;;
val parse_exp : (lexeme -> bool) -> chaine_lexer -> expression = <fun>
Notons que le lexème qui a déterminé l'arrêt du parcours n'a
pas servi à construire l'expression. Il faut donc restaurer son
indice de début (variable p) pour qu'il puisse être
traité par la suite.
Passons maintenant à l'analyse d'une ligne d'instruction :
# let parse_inst cl = match lexer cl with
Lident s -> ( match s with
"REM" -> Rem (extrait (fun _ -> true) cl)
| "GOTO" -> Goto (match lexer cl with
Lint p -> p
| _ -> raise ParseErreur)
| "INPUT" -> Input (match lexer cl with
Lident v -> v
| _ -> raise ParseErreur)
| "PRINT" -> Print (parse_exp ((=) Lfin) cl)
| "LET" ->
let l2 = lexer cl and l3 = lexer cl
in ( match l2 ,l3 with
(Lident v,Lsymbol "=") -> Let (v,parse_exp ((=) Lfin) cl)
| _ -> raise ParseErreur )
| "IF" ->
let test = parse_exp ((=) (Lident "THEN")) cl
in ( match ignore (lexer cl) ; lexer cl with
Lint n -> If (test,n)
| _ -> raise ParseErreur )
| _ -> raise ParseErreur )
| _ -> raise ParseErreur ;;
val parse_inst : chaine_lexer -> instruction = <fun>
Enfin, voici la fonction principale d'analyse syntaxique des commandes
entrées par l'utilisateur depuis la boucle d'interaction :
# let parse str =
let cl = init_lex str
in match lexer cl with
Lint n -> Ligne { num=n ; inst=parse_inst cl }
| Lident "LIST" -> List
| Lident "RUN" -> Run
| Lident "END" -> End
| _ -> raise ParseErreur ;;
val parse : string -> phrase = <fun>
Évaluation
Un programme Basic est constitué d'une suite de lignes
d'instruction. Son exécution démarre à la première
ligne. L'interprétation d'une ligne de programme consiste donc à
effectuer le travail demandé par l'instruction qui s'y trouve. Il y a
trois familles d'instruction : les entrées-sorties (PRINT et
INPUT), les déclarations ou modifications de variables
(LET) et les branchements (GOTO et THEN). Les
instructions d'entrées-sorties gèrent l'interaction avec l'utilisateur
et exécuteront les fonctions équivalentes en Objective CAML.
Les déclarations de variables et leurs modifications ont besoin de
savoir calculer la valeur d'une expression arithmétique et de
connaître la localisation mémoire de la variable. L'évaluation d'une
expression retourne une valeur entière ou booléenne ou des
chaînes de caractères. Nous les regroupons sous le type
valeur.
# type valeur = Vint of int | Vstr of string | Vbool of bool ;;
La déclaration d'une variable doit pouvoir réserver une place mémoire
pour le rangement de la valeur qui lui est attribuée. De même la
modification d'une variable nécessite la modification de la valeur
associée à son nom. Pour cela l'évaluation d'un programme Basic
utilise un environnement qui contient la liaison entre un nom
de variable et sa valeur. On le représente par une liste
d'associations, liste de couples (nom,valeur) :
# type environnement = (string * valeur) list ;;
On accède au contenu d'une variable par son nom. La modification de la
valeur d'une variable change l'association.
Les instructions de branchements, inconditionnels ou conditionnels,
précisent à quel numéro de ligne l'exécution du programme doit se
poursuivre. Par défaut, la nouvelle instruction à exécuter est la
suivante. Pour cela il est nécessaire de conserver le numéro de la
prochaine ligne à exécuter.
La structure de liste d'instructions qui représente le programme
édité sous la boucle d'interaction ne convient pas à une
exécution raisonnablement efficace du programme. En effet, pour
réaliser les instructions de saut (If et Goto) nous
devrions reparcourir la totalité de la liste d'instructions pour
trouver la ligne indiquée par le saut. Il est possible d'accéder
directement à une ligne indiquée par une instruction de saut en
substituant à la structure de liste, une structure de
tableau et en utilisant les indices de localisation des instructions
à la place des numéros de ligne. Pour cela, nous soumettrons
l'ensemble des instructions du programme à un prétraitement, dit
d'assemblage avant chaque exécution réclamée par une
commande RUN. Pour des raisons de commodité que nous
expliquons au paragraphe suivant, nous représentons un programme
assemblé pour l'exécution non pas comme un simple tableau
d'instructions, mais comme un tableau de lignes :
# type code = ligne array ;;
Comme pour la calculatrice des chapitres précédents, l'évaluateur
manipule un état que l'évaluation de chaque instruction
modifie. Les informations à connaître à chaque instant sont
le programme en entier, la prochaine ligne à exécuter et les
valeurs des variables. Le programme exécuté n'est pas exactement
celui construit sous la boucle d'interaction : plutôt que
d'exécuter une liste d'instructions, nous manipulerons un tableau
d'instructions. L'état d'exécution d'un
programme est donc :
# type etat_exec = { ligne:int ; xprog:code ; xenv:environnement } ;;
Il y a deux sources d'erreur à l'évaluation d'une ligne de programme :
le calcul d'une expression et un branchement sur une ligne qui
n'existe pas. Il nous faut donc les gérer pour que
l'interprète s'arrête correctement en affichant un message
d'erreur. On définit une exception et une fonction la déclenchant
tout en indiquant à quel numéro de ligne elle s'est produite.
# exception RunErreur of int
let runerr n = raise (RunErreur n) ;;
exception RunErreur of int
val runerr : int -> 'a = <fun>
Assemblage
Le processus d'assemblage d'un programme donné sous forme de liste
de lignes numérotées (type program) consiste à
transformer cette liste en tableau puis à ajuster les instructions de
saut. Pour réaliser cet ajustement, il suffit de conserver
l'association entre les numéros de lignes et l'indice correspondant
du tableau. C'est pour obtenir facilement cette association que nous
construisons un tableau de lignes numérotées. Pour retrouver
l'indice auquel est associé une ligne, on parcourt ce tableau. Si le
numéro de ligne recherché n'est pas trouvé, on lui assigne, par
convention, l'indice erroné -1.
# exception Resultat_cherche_indice of int ;;
exception Resultat_cherche_indice of int
# let cherche_indice tprog num_ligne =
try
for i=0 to (Array.length tprog)-1 do
let mun_i = tprog.(i).num
in if mun_i=num_ligne then raise (Resultat_cherche_indice i)
else if mun_i>num_ligne then raise (Resultat_cherche_indice (-1))
done ;
(-1 )
with Resultat_cherche_indice i -> i ;;
val cherche_indice : ligne array -> int -> int = <fun>
# let assemble prog =
let tprog = Array.of_list prog in
for i=0 to (Array.length tprog)-1 do
match tprog.(i).inst with
Goto n -> let indice = cherche_indice tprog n
in tprog.(i) <- { tprog.(i) with inst = Goto indice }
| If(c,n) -> let indice = cherche_indice tprog n
in tprog.(i) <- { tprog.(i) with inst = If (c,indice) }
| _ -> ()
done ;
tprog ;;
val assemble : ligne list -> ligne array = <fun>
Évaluation des expressions
La fonction d'évaluation des expressions parcourt en
profondeur
l'arbre de syntaxe abstraite et effectue les opérations
indiquées à chaque noeud de l'arbre.
L'exception RunErreur est déclenchée dans les cas
suivants : incohérence de type, division par zéro, variable non
déclarée.
# let rec eval_exp n envt expr = match expr with
ExpInt p -> Vint p
| ExpVar v -> ( try List.assoc v envt with Not_found -> runerr n )
| ExpUnr (OPPOSE,e) ->
( match eval_exp n envt e with
Vint p -> Vint (-p)
| _ -> runerr n )
| ExpUnr (NON,e) ->
( match eval_exp n envt e with
Vbool p -> Vbool (not p)
| _ -> runerr n )
| ExpStr s -> Vstr s
| ExpBin (e1,op,e2)
-> match eval_exp n envt e1 , op , eval_exp n envt e2 with
Vint v1 , PLUS , Vint v2 -> Vint (v1 + v2)
| Vint v1 , MOINS , Vint v2 -> Vint (v1 - v2)
| Vint v1 , MULT , Vint v2 -> Vint (v1 * v2)
| Vint v1 , DIV , Vint v2 when v2<>0 -> Vint (v1 / v2)
| Vint v1 , MOD , Vint v2 when v2<>0 -> Vint (v1 mod v2)
| Vint v1 , EGAL , Vint v2 -> Vbool (v1 = v2)
| Vint v1 , DIFF , Vint v2 -> Vbool (v1 <> v2)
| Vint v1 , INF , Vint v2 -> Vbool (v1 < v2)
| Vint v1 , SUP , Vint v2 -> Vbool (v1 > v2)
| Vint v1 , INFEQ , Vint v2 -> Vbool (v1 <= v2)
| Vint v1 , SUPEQ , Vint v2 -> Vbool (v1 >= v2)
| Vbool v1 , ET , Vbool v2 -> Vbool (v1 && v2)
| Vbool v1 , OU , Vbool v2 -> Vbool (v1 || v2)
| Vstr v1 , PLUS , Vstr v2 -> Vstr (v1 ^ v2)
| _ , _ , _ -> runerr n ;;
val eval_exp : int -> (string * valeur) list -> expression -> valeur = <fun>
Évaluation des instructions
Pour réaliser la fonction d'évaluation d'une ligne d'instruction,
nous avons besoin de quelques fonctions auxiliaires.
On ajoute une nouvelle association dans un environnement en supprimant
éventuellement la liaison d'une variable de même nom :
# let rec ajoute v e env = match env with
[] -> [v,e]
| (w,f)::l -> if w=v then (v,e)::l else (w,f)::(ajoute v e l) ;;
val ajoute : 'a -> 'b -> ('a * 'b) list -> ('a * 'b) list = <fun>
Enfin l'affichage d'une valeur d'un entier ou d'une chaîne de
caractères sera utile pour l'instruction PRINT.
# let print_valeur v = match v with
Vint n -> print_int n
| Vbool true -> print_string "true"
| Vbool false -> print_string "false"
| Vstr s -> print_string s ;;
val print_valeur : valeur -> unit = <fun>
L'évaluation d'une instruction est une transition menant d'un
état à un autre. En particulier sont modifiés d'une part
l'environnement si l'instruction est une affectation et d'autre part
la prochaine ligne à exécuter. Par convention, si la prochaine ligne
à exécuter sort du tableau contenant le code du programme, sa
valeur est -1.
# let ligne_suivante etat =
let n = etat.ligne+1 in
if n < Array.length etat.xprog then n else -1 ;;
val ligne_suivante : etat_exec -> int = <fun>
# let eval_inst etat =
match etat.xprog.(etat.ligne).inst with
Rem _ -> { etat with ligne = ligne_suivante etat }
| Print e -> print_valeur (eval_exp etat.ligne etat.xenv e) ;
print_newline () ;
{ etat with ligne = ligne_suivante etat }
| Let(v,e) -> let ev = eval_exp etat.ligne etat.xenv e
in { etat with ligne = ligne_suivante etat ;
xenv = ajoute v ev etat.xenv }
| Goto n -> { etat with ligne = n }
| Input v -> let x = try read_int ()
with Failure "int_of_string" -> 0
in { etat with ligne = ligne_suivante etat;
xenv = ajoute v (Vint x) etat.xenv }
| If (t,n) -> match eval_exp etat.ligne etat.xenv t with
Vbool true -> { etat with ligne = n }
| Vbool false -> { etat with ligne = ligne_suivante etat }
| _ -> runerr etat.ligne ;;
val eval_inst : etat_exec -> etat_exec = <fun>
À chaque appel, la fonction de transition eval_inst
cherche la ligne à exécuter (variable lc) et le
numéro de la ligne suivante (variable ns). Si la
dernière ligne du programme est atteinte, on attribue à
ns la valeur -1. Cela nous permettra d'arrêter
l'exécution.
Évaluation d'un programme
On applique récursivement les transitions jusqu'à obtenir un
état où le numéro de la ligne courante est -1.
# let rec run etat =
if etat.ligne = -1 then etat else run (eval_inst etat) ;;
val run : etat_exec -> etat_exec = <fun>
Mise en oeuvre
Il ne nous reste plus qu'à réaliser un mini-éditeur et
d'assembler toutes les briques réalisées dans les sections
précédentes.
La fonction inserer ajoute, à la bonne place, une nouvelle
ligne dans un programme.
# let rec inserer ligne p = match p with
[] -> [ligne]
| l::prog ->
if l.num < ligne.num then l::(inserer ligne prog)
else if l.num=ligne.num then ligne::prog
else ligne::l::prog ;;
val inserer : ligne -> ligne list -> ligne list = <fun>
La fonction print_prog affiche le source d'un programme.
# let print_prog prog =
let print_ligne x = print_string (pp_ligne x) ; print_newline () in
print_newline () ;
List.iter print_ligne prog ;
print_newline () ;;
val print_prog : ligne list -> unit = <fun>
La fonction une_commande traite l'ajout d'une ligne ou le
lancement d'une commande. Elle agit sur l'état de la boucle
d'interaction constitué d'un programme et d'un environnement. Cet
état, représenté par le type etat_boucle, n'est pas
celui de l'évaluation d'un programme.
# type etat_boucle = { prog:program; env:environnement } ;;
# exception Fin ;;
# let une_commande etat =
print_string "> " ; flush stdout ;
try
match parse (input_line stdin) with
Ligne l -> { etat with prog = inserer l etat.prog }
| List -> (print_prog etat.prog ; etat )
| Run
-> let tprog = assemble etat.prog in
let xetat = run { ligne = 0; xprog = tprog; xenv = etat.env } in
{etat with env = xetat.xenv }
| End -> raise Fin
with
LexerErreur -> print_string "Illegal character\n"; etat
| ParseErreur -> print_string "syntax error\n"; etat
| RunErreur n ->
print_string "runtime error at line ";
print_int n ;
print_string "\n";
etat ;;
val une_commande : etat_boucle -> etat_boucle = <fun>
La fonction principale est la fonction go qui lance la boucle
d'interaction de notre Basic.
# let go () =
try
print_string "Mini-BASIC version 0.1\n\n";
let rec loop etat = loop (une_commande etat) in
loop { prog = []; env = [] }
with Fin -> print_string "A bientôt...\n";;
val go : unit -> unit = <fun>
La boucle est réalisée par la fonction locale loop. On en
sort lorsque l'exception Fin a été déclenchée par la
fonction une_commande.
Exemple : C+/C-
On reprend l'exemple du jeu C+/C- décrit au chapitre 3,
page ??. Voici le programme Basic équivalent au programme
Objective CAML donné :
10 PRINT "Donner le nombre cache : "
20 INPUT N
30 PRINT "Donner un nombre : "
40 INPUT R
50 IF R = N THEN 110
60 IF R < N THEN 90
70 PRINT "C-"
80 GOTO 30
90 PRINT "C+"
100 GOTO 30
110 PRINT "BRAVO"
Voici, pour finir, la trace de l'exécution de ce programme.
> RUN
Donner le nombre caché :
64
Donner un nombre :
88
C-
Donner un nombre :
44
C+
Donner un nombre :
64
BRAVO
Pour en faire plus
Le Basic que nous venons de programmer reste minimal. Pour ceux qui
veulent aller plus loin, nous proposons en exercice quelques pistes
pour enrichir l'évaluateur.
- Les flottants : tel quel, notre langage ne connaît que
les entiers, les chaînes et les booléens. Ajouter les flottants
ainsi que leurs principales opérations dans la grammaire du langage.
Outre l'analyse lexicale, il faut modifier l'évaluation en tenant
compte des conversions implicites entre entiers et flottants.
- Les tableaux : il s'agit ici d'ajouter à la syntaxe
l'instruction DIM var[x] qui permet de déclarer un tableau
var de taille x et l'expression var[i] qui
référence le ième élément du tableau var.
- Directives : nous devrions aussi ajouter les directives
SAVE "nom_fichier" et LOAD "nom_fichier" qui
respectivement enregistre ou charge un programme Basic sur ou depuis
le disque dur.
- Sous-programmes : l'appel à un sous-programme s'effectue
en utilisant l'instruction GOSUB numéro de ligne qui effectue
un branchement à ce numéro de ligne tout en conservant le numéro de la
ligne d'appel. L'instruction RETURN reprend l'exécution à la
ligne suivant la dernière instruction GOSUB exécutée si elle existe
et sort du programme sinon. Pour ajouter cette possibilité, il
faudra gérer dans l'évaluation, en plus de l'environnement, une
pile contenant les adresses de retour des différents appels à GOSUB. L'instruction GOSUB permet de définir des
sous-programmes récursifs.